When approaching CRM analysis using machine learning, it helps to first understand and categorize the problem.
Each of the quadrants in the diagram below has it's own unique set of data collection and processing requirements.
Each of the quadrants in the diagram below has it's own unique set of data collection and processing requirements.
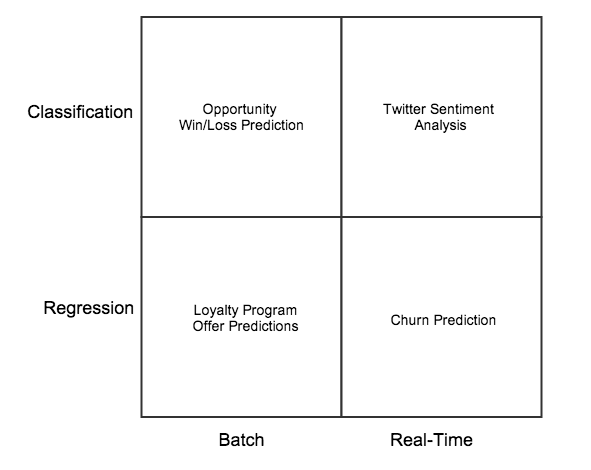
Classification problems result in labeling data.
Regression problems result in making a numeric prediction, such as a probability.
Batch problems are done "offline" and often use data sets spanning several days or years. The value of batch problems increases with the number of unique data points that can be added to the training set.
Real-Time problems operate on smaller data samples, but are often trained on a very large corpus of data, such as log file history or social media posts.
Some examples of machine learning problems at the intersections of these dimensions:
Opportunity Win/Loss (Batch Classification): This could be a weekly exercise of reviewing pipeline opportunities and letting a classification algorithm predict "Win" or "Loss" based on past Opportunities.
Loyalty Programs (Batch Regression): An airline may run monthly batch predictions to determine how many reward points might incentivize frequent flyers to accept an offer.
Twitter Sentiment (Real-Time Classification): Analyzing the "firehose" of tweets to determine if customers are happy or upset with a particular brand.
Churn Prediction (Real-Time Regression): A call center may make make predictions on whether a customer is likely to attrit based on real-time information. Higher probably churn predictions may result in authorizing Customer Service Representatives to offer retention incentives.
Note: Real-Time machine learning can be further sub-categorized into when the actual training takes place. Some applications will evaluate data in real-time using a previously trained, static model that goes relatively unchanged. For example, weather predictions.
Adaptive learning algorithms simultaneously evaluate real-time data streams AND re-train the evaluation model, typically based on a pre-defined trailing sample window, or when sufficient human feedback signal has been collected to warrant a retraining.
Regression problems result in making a numeric prediction, such as a probability.
Batch problems are done "offline" and often use data sets spanning several days or years. The value of batch problems increases with the number of unique data points that can be added to the training set.
Real-Time problems operate on smaller data samples, but are often trained on a very large corpus of data, such as log file history or social media posts.
Some examples of machine learning problems at the intersections of these dimensions:
Opportunity Win/Loss (Batch Classification): This could be a weekly exercise of reviewing pipeline opportunities and letting a classification algorithm predict "Win" or "Loss" based on past Opportunities.
Loyalty Programs (Batch Regression): An airline may run monthly batch predictions to determine how many reward points might incentivize frequent flyers to accept an offer.
Twitter Sentiment (Real-Time Classification): Analyzing the "firehose" of tweets to determine if customers are happy or upset with a particular brand.
Churn Prediction (Real-Time Regression): A call center may make make predictions on whether a customer is likely to attrit based on real-time information. Higher probably churn predictions may result in authorizing Customer Service Representatives to offer retention incentives.
Note: Real-Time machine learning can be further sub-categorized into when the actual training takes place. Some applications will evaluate data in real-time using a previously trained, static model that goes relatively unchanged. For example, weather predictions.
Adaptive learning algorithms simultaneously evaluate real-time data streams AND re-train the evaluation model, typically based on a pre-defined trailing sample window, or when sufficient human feedback signal has been collected to warrant a retraining.

 RSS Feed
RSS Feed